It took eleven months for Google’s artificial intelligence to master and then dominate humans at Quake III Arena, a game that combines multi-strategy and one-on-one combat. A real feat because the game cards evolve permanently and cannot be memorized by the AI.
Researchers from the DeepMind artificial intelligence laboratory in London have just published the results of their research on machine learning and video games. After mastering the one-on-one StarCraft II game with its AlphaStar artificial intelligence, the team pushed the search further with team games in Quake III Arena.
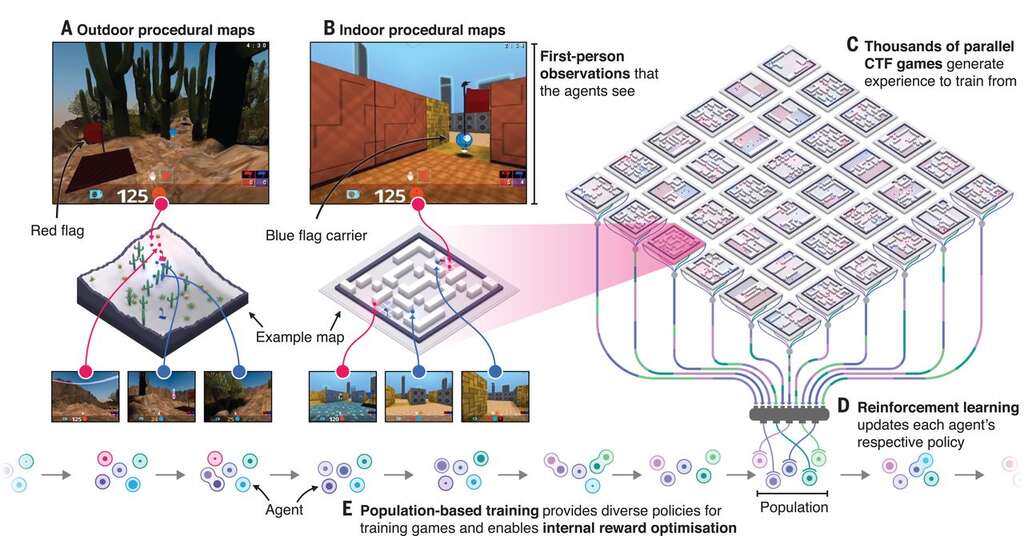
The researchers were particularly interested in the ” capture the flag ” mode, the capture of the flag where the rules are straightforward. The players are divided into two teams and must work together to pick up the flag in the opposing base and bring it back into theirs while protecting their flag.
The DeepMind researchers have created a team of independent “agents,” each of whom must learn and implement their strategies while cooperating with their teammates. To make things worse, and to prevent the AI from creating techniques that are too specific to certain configurations, the map is randomly generated at each game.
Artificial intelligence that learns to play without any instructions
Agents must learn to see, move, cooperate, and fight alone. The only return they have to judge their performance is when their team wins or not. Their learning was based on the technique of deep learning, with neural networks, and 450,000 parts of the game. The researchers were able to observe the implementation of strategies by their agents with, for example, a neuron that is activated when the flag is taken from the base of the agent, or another that activates if one of his teammates holds the enemy flag.
The researchers organized a tournament with 40 human players, randomly chosen to be enemies or teammates with the agents. Since AI has a reaction time that is vastly superior to humans, researchers have slowed agents to allow balanced competition.
Despite this, the agents crushed the human players, winning 79% of the games against opponents with an outstanding level. The score increases to 88% against middle-level humans. Tournament participants even said in a poll that agents played more collaboratively than human players.
An ability to collaborate without direct communication
Unlike humans, agents could not communicate outside of the game. Their method of collaboration was, therefore, to respond as best as possible to the actions of their teammates. This means that by allowing agents to share their strategies, they could still improve their performance. The current system is so effective that it has performed very well on the full version of Quake III Arena, with cards used in professional games, new multiplayer modes, and more bonuses in-game.
These results show the progress of research on artificial intelligence in virtual universes. However, researchers do not study video games as an end in themselves, but as a starting point, thanks to a simplified environment compared to the real world. Such advances could then be extended to robots, for example, to move goods into warehouses and allow them to work in groups.